결정 트리
와인 문제
캔에 인쇄된 알콜 도수, 당도, ph 값으로 와인 종류 (레드/화이트) 구별
0.0 -> 레드 (음성)
1.0 -> 화이트 (양성)
레드와인과 화이트와인을 분류해내는 이진 분류 문제
로지스틱 회귀로 해결해보기
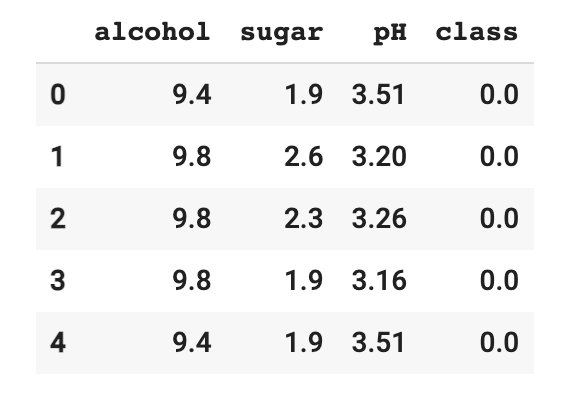
- 데이터 준비 후 훈련세트와 테스트세트 나누기 ```py import pandas as pd wine = pd.read_csv(‘https://bit.ly/wine_csv_data’) wine.head()
data = wine[[‘alcohol’,’sugar’,’pH’]].to_numpy() target = wine[‘class’].to_numpy()
from sklearn.model_selection import train_test_split train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
2. alcohol, suga, ph 의 특성이 모두 다르므로 특성을 표준화 (데이터 전처리)
```py
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
- 로지스틱 회귀 모델 훈련
from sklearn.linear_model import LogisticRegression lr = LogisticRegression() lr.fit(train_scaled, train_target) print(lr.score(train_scaled, train_target)) print(lr.score(test_scaled, test_target)) print(lr.coef_, lr.intercept_)
0.7808350971714451
0.7776923076923077
[[ 0.51270274 1.6733911 -0.68767781]] [1.81777902] # 계수와 절편
점수가 낮고 , 둘다 낮으니 과소적합..
- 규제 매개변수 c 의 값을 바꾸거나,
- 다른 알고리즘 사용,
- 다항특성 추가 등
여러 방법으로 시도해 볼 수 있음.
로지스틱 회귀의 문제점?
우리는 왜 로지스틱 모델이 저런 계수와 절편값을 구해냈는지 ‘직관적으로’ 알아내지 못한다. 알콜 도수와 당도가 높을수록 레드와인.. 이런식으로 추측할 뿐이다. 정확히 이 숫자들이 어떤 의미인지 명확하게 어렵다.
결정트리 모델
-
이유를 설명해 주는 모델
-
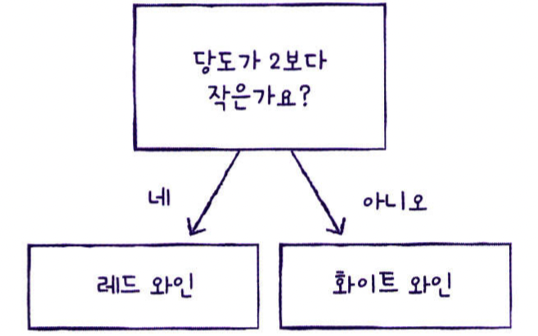
데이터를 잘 나눌 수 있는 질문을 찾아 계속 질문을 추가하여 분류 정확도를 높힐 수 있다.
- 로지스틱 회귀모델을 훈련시키는 방식과 동일. 사이킷런이 이 트리 알고리즘을 제공한다.
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
# 점수가 높지만, 과대적합
0.996921300750433
0.8592307692307692
- 모델을 그림으로 표현해준다.
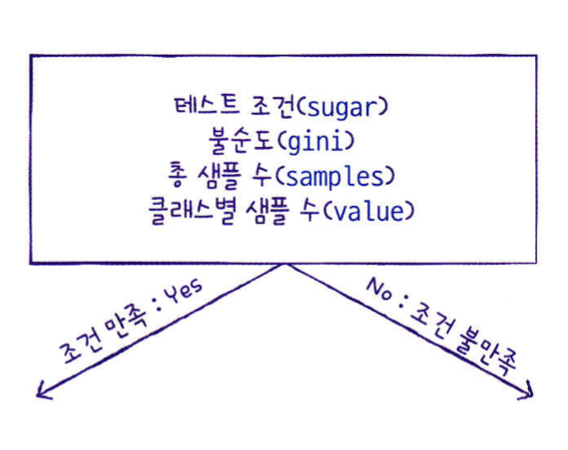
- 루트노드와 리프노드
- 하나의 노드는 하나의 질문이라고 볼 수있음. 훈련 데이터의 특성에 대한 테스트 결과를 나타낸다. 예를들어 현재 샘플의 당도가 -0.5 보다 작은지 묻고, true/false로 분기하여 branch를 만든다.
- 보기 편하도록 바꿔보자
depth를 1로 주고(max_depth=1)
class별 노드 색 칠하기 (filled=True)
특성의 이름 전달해서 표기(feature_names=[‘alcohol’, ‘sugar’,’pH’])
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar','pH'])
plt.show()
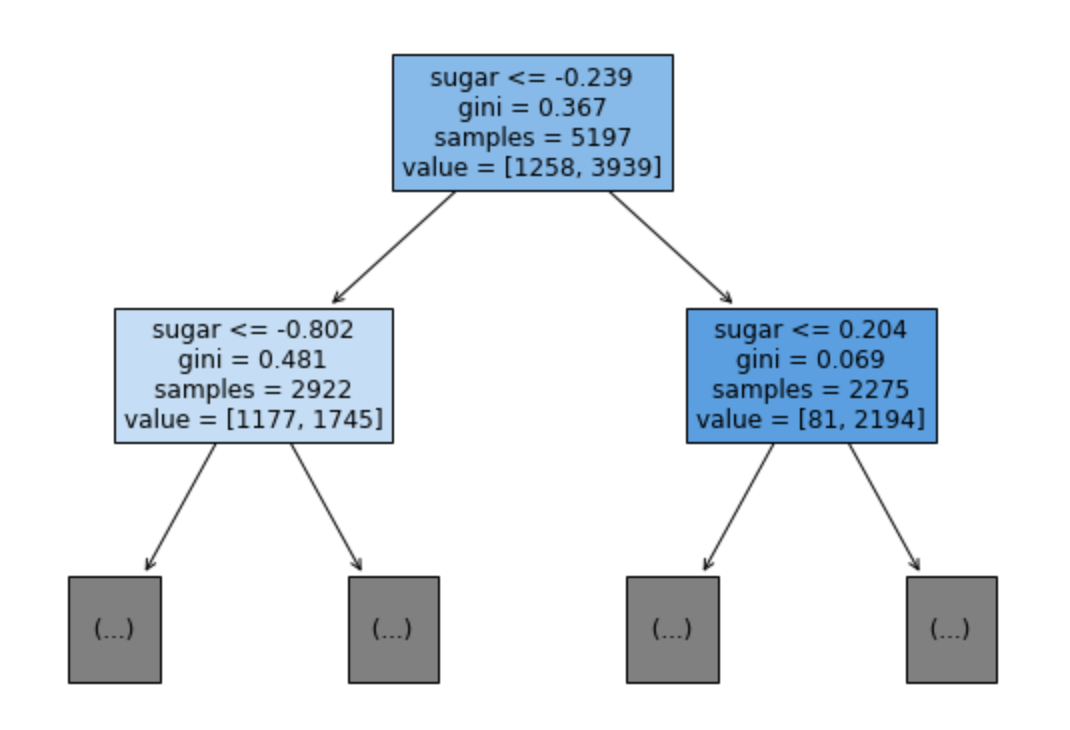
이렇게 분기를 해놓으면, 새로운 데이터를 예측하기 위해 주어진 데이터 포인트가 특성을 분할한 영역들 중 어디에 놓이는지를 확인하면 됩니다. 그래서 그 영역의 타깃값 중 다수(순수 노드라면 하나)인 것을 예측 결과로 합니다. 루트 노드에서 시작해 테스트의 결과에 따라 왼쪽 또는 오른쪽으로 트리를 탐색해나가는 식으로 영역을 찾을 수 있습니다.
같은 방법으로 회귀 문제에도 트리를 사용할 수 있습니다. 예측을 하려면 각 노드의 테스트 결과에 따라 트리를 탐색해나가고 새로운 데이터 포인트에 해당되는 리프 노드를 찾습니다. 찾은 리프 노드의 훈련 데이터 평균 값이 이 데이터 포인트의 출력이 됩니다.
그렇다면 어떻게 분기할까?
위 그림에서 gini가 그 역할을 한다.
gini
- gini는 gini impurity(지니 불순도)
- DecisionTreeClassifier 클래스의 criterion 매개변수의 기본값.
- 노드에서 데이터가 분할할 기준을 정하는 것
지니 불순도 = 1 - ((음성 클래스 비율)^2 + (양성 클래스 비율)^2)
# 루트 노드의 지니 불순도
1 - ((1258/5197)^2 + (3939/5197)^2) = 0.367
- 결정 트리 모델은 부모 노드와 자식 노드의 불순도 차이가 가능한 크도록 트리를 성장시킨다.
부모 노드와 자식 노드의 불순도 차이 계산법 : 자식 노드의 불순도를 샘플 개수에 비례하여 모두 더하고, 부모의 불순도에서 빼준다.
부모의 불순도 - (왼쪽 노드 샘플 수 / 부모 노드의 샘플 수) * 왼쪽 노드 불순도 - (오른쪽 노드 샘플 수 / 부모 노드의 샘플 수) * 도른쪽 노드 불순도
= 0.066
이 차이를 정보 이득이라고 부르는데, 결정 트리 알고리즘은 이 정보 이득이 최대가 되도록 데이터를 나눈다.
#
또 다른 분기방법?
criterion = 'entropy'
엔트로피 불순도
- 지니 불순도와 마찬가지로 노드의 클래스비율을 사용하지만 지니 불순도 처럼 제곱이 아니라 밑이 2인 로그 아용

가지치기?
결정트리를 가지치기 하지 않으면 모든 리프노드가 한개의 타깃값을 가질 때 까지, 즉 순수 노드가 될 때 까지 트리를 만든다.
순수 노드로 이루어진 트리는 훈련 세트에 완벽하게 맞는다는 의미이고, 과대적합을 나타낸다.
가치를 치는 방법
트리 생성을 일찍 중단하는 사전 가지치기
- 자라나는 트리의 깊이를 지정
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
# 결과
0.8454877814123533
0.8415384615384616
- 가지치기 한 그래프
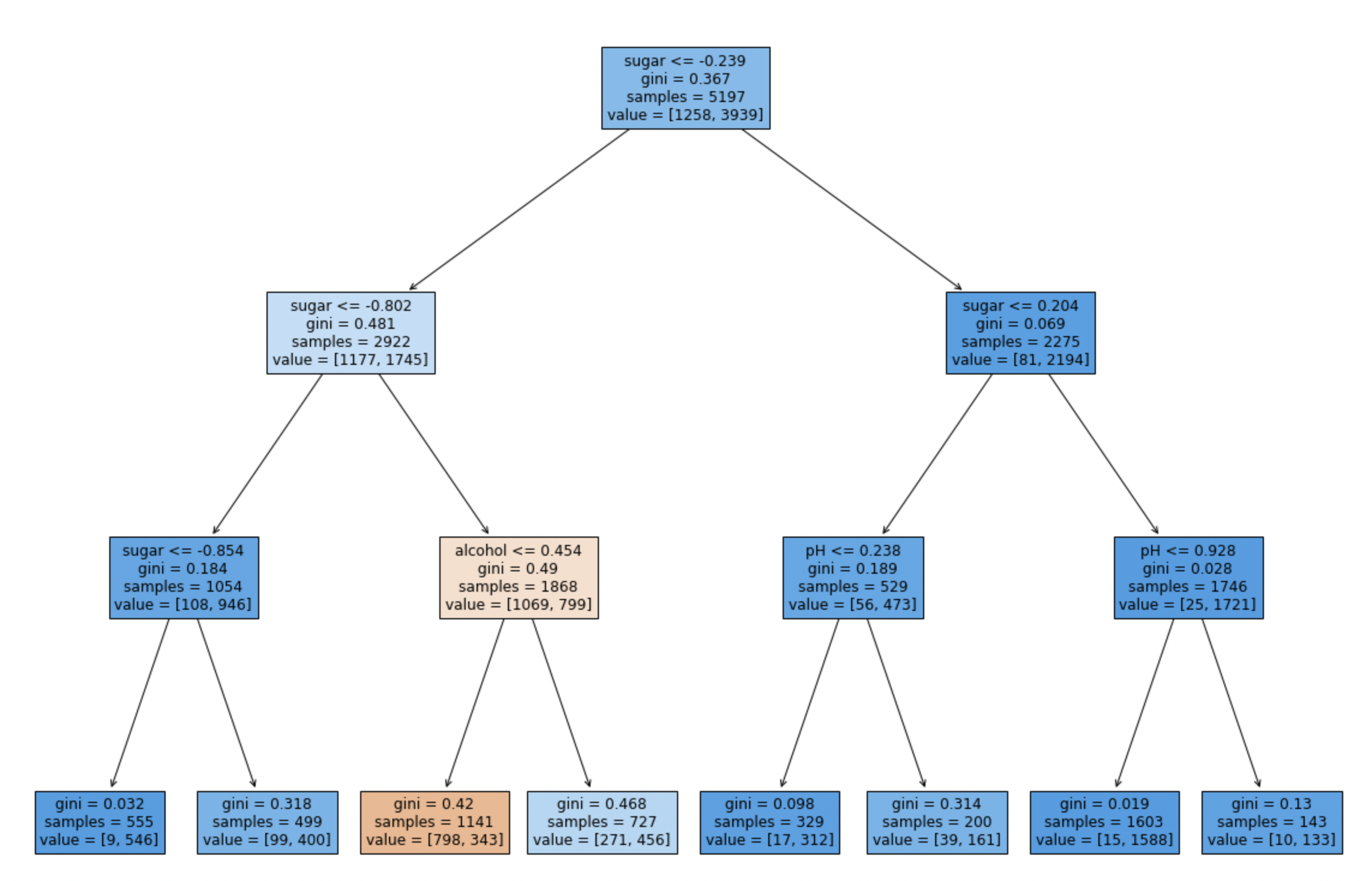
트리를 만은 후 데이터 포인트가 적은 노드를 삭제하거나 병합하는 사후 가지치기
사이킷런 미제공